![]()


Urban

Effects

People
World News

MIT engineers design proteins by their motion, not just their shape | MIT News
Proteins are far more than nutrients we track on a food label. Present in every cell of our bodies, they work like nature’s molecular machines. They walk, stretch, bend, and flex to do their jobs, pumping blood, fighting disease, building tissue, and many other jobs too small for the eye to see. Their power…

Seeing sounds | MIT News
Growing up in Mexico and Texas, Mariano Salcedo ’25 couldn’t readily indulge his passion for creating music. “There are no bands in Mexican public schools,” he says. While some families could pay for instruments and lessons, others, like Salcedo’s, were less fortunate.“I’ve always loved music,” he continues. “I was a listener.” Salcedo, the Alex Rigopulos…
Cohere AI Releases Cohere Transcribe: A SOTA Automatic Speech Recognition (ASR) Model Powering Enterprise Speech Intelligence
In the landscape of enterprise AI, the bridge between unstructured audio and actionable text has often been a bottleneck of proprietary APIs and complex cascaded pipelines. Today, Cohere—a company traditionally known for its text-generation and embedding models—has officially stepped into the Automatic Speech Recognition (ASR) market with the release of their latest model ‘Cohere…
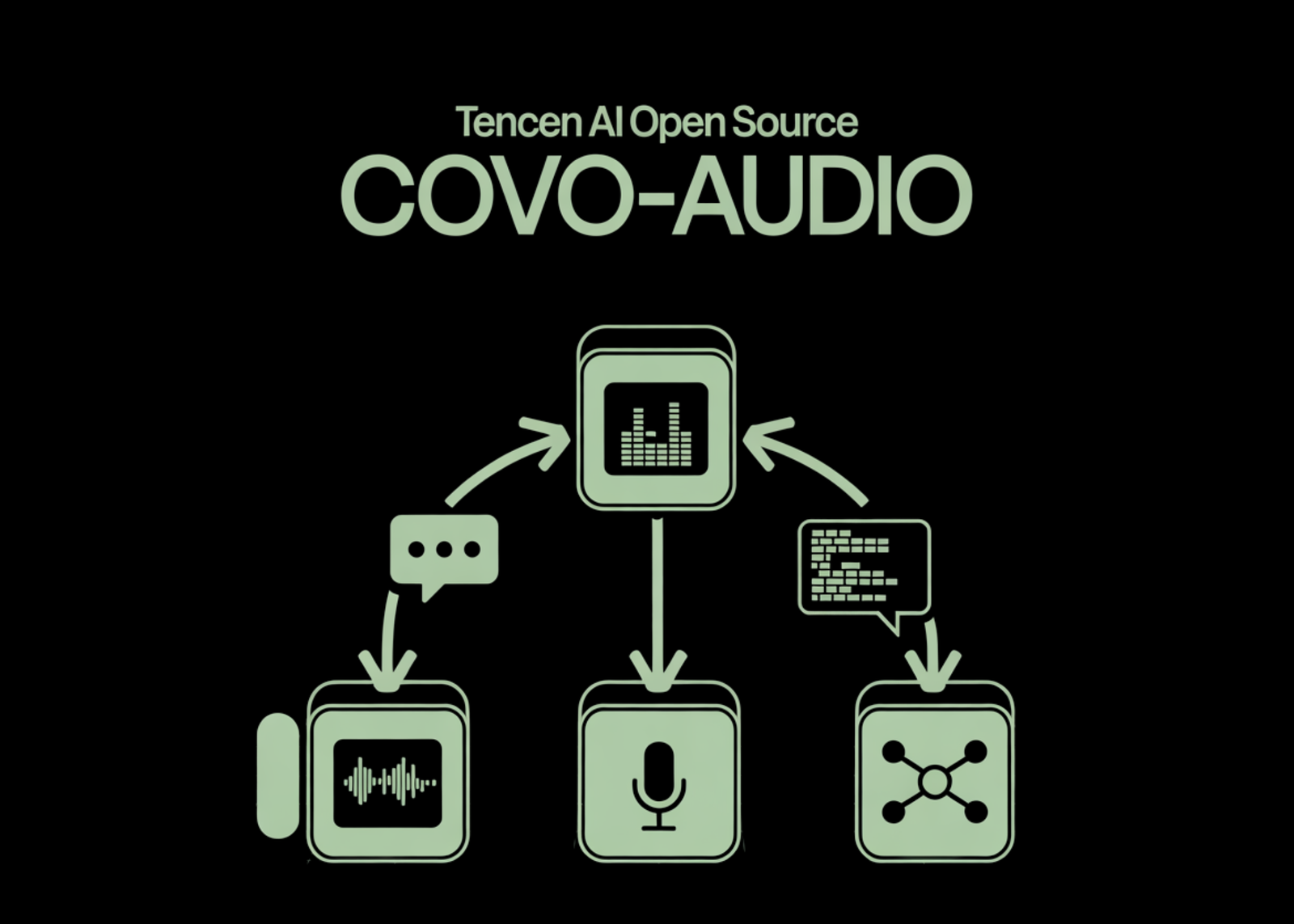
Tencent AI Open Sources Covo-Audio: A 7B Speech Language Model and Inference Pipeline for Real-Time Audio Conversations and Reasoning
Tencent AI Lab has released Covo-Audio, a 7B-parameter end-to-end Large Audio Language Model (LALM). The model is designed to unify speech processing and language intelligence by directly processing continuous audio inputs and generating audio outputs within a single architecture. System Architecture The Covo-Audio framework consists of four primary components designed for seamless cross-modal interaction:…

AI system learns to keep warehouse robot traffic running smoothly | MIT News
Inside a giant autonomous warehouse, hundreds of robots dart down aisles as they collect and distribute items to fulfill a steady stream of customer orders. In this busy environment, even small traffic jams or minor collisions can snowball into massive slowdowns.To avoid such an avalanche of inefficiencies, researchers from MIT and the tech firm…
How to Build a Vision-Guided Web AI Agent with MolmoWeb-4B Using Multimodal Reasoning and Action Prediction
def parse_click_coords(action_str): “”” Extract normalised (x, y) coordinates from a click action string. e.g., ‘click(0.45, 0.32)’ -> (0.45, 0.32) Returns None if the action is not a click. “”” match = re.search(r”click\(\s*([\d.]+)\s*,\s*([\d.]+)\s*\)”, action_str) if match: return float(match.group(1)), float(match.group(2)) return None def parse_action_details(action_str): “”” Parse a MolmoWeb action string into a structured dict. Returns: {“type”:…
58,790
Photos taken
15,832
Places visited
12,352
Contests
90,327
Enrolled people











