![]()

Beyond Accuracy: 5 Metrics That Actually Matter for AI Agents
Image by Editor
Introduction
AI agents, or autonomous systems powered by agentic AI, have reshaped the current landscape of AI systems and deployments. As these systems become more capable, we also need specialized evaluation metrics that quantify not only correctness, but also procedural reasoning, reliability, and efficiency. While accuracy is one of the most common metrics used in static large language model evaluations, agent evaluations often require additional measures focused on action quality, tool use, and trajectory efficiency — especially when building modern AI agents.
This article lists five such metrics, along with further readings to dive deeper into each.
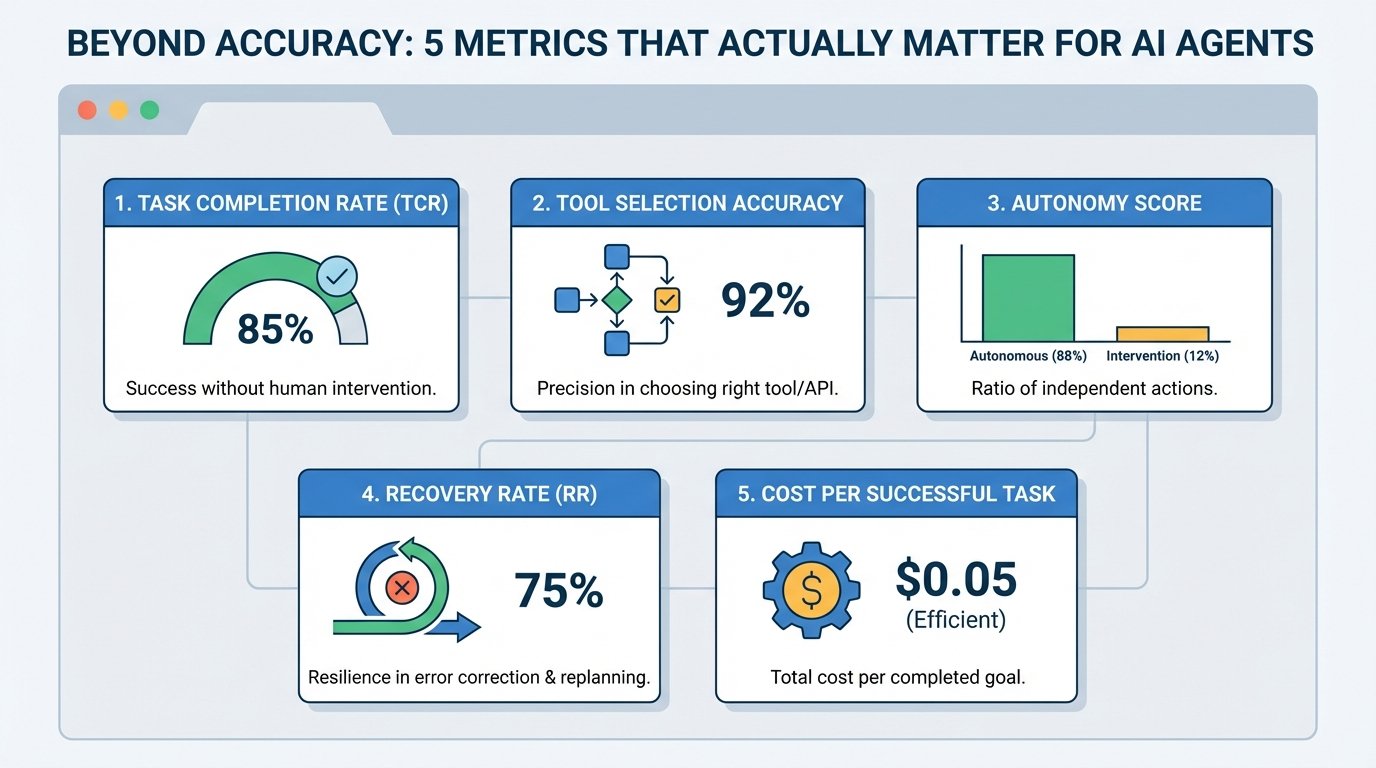
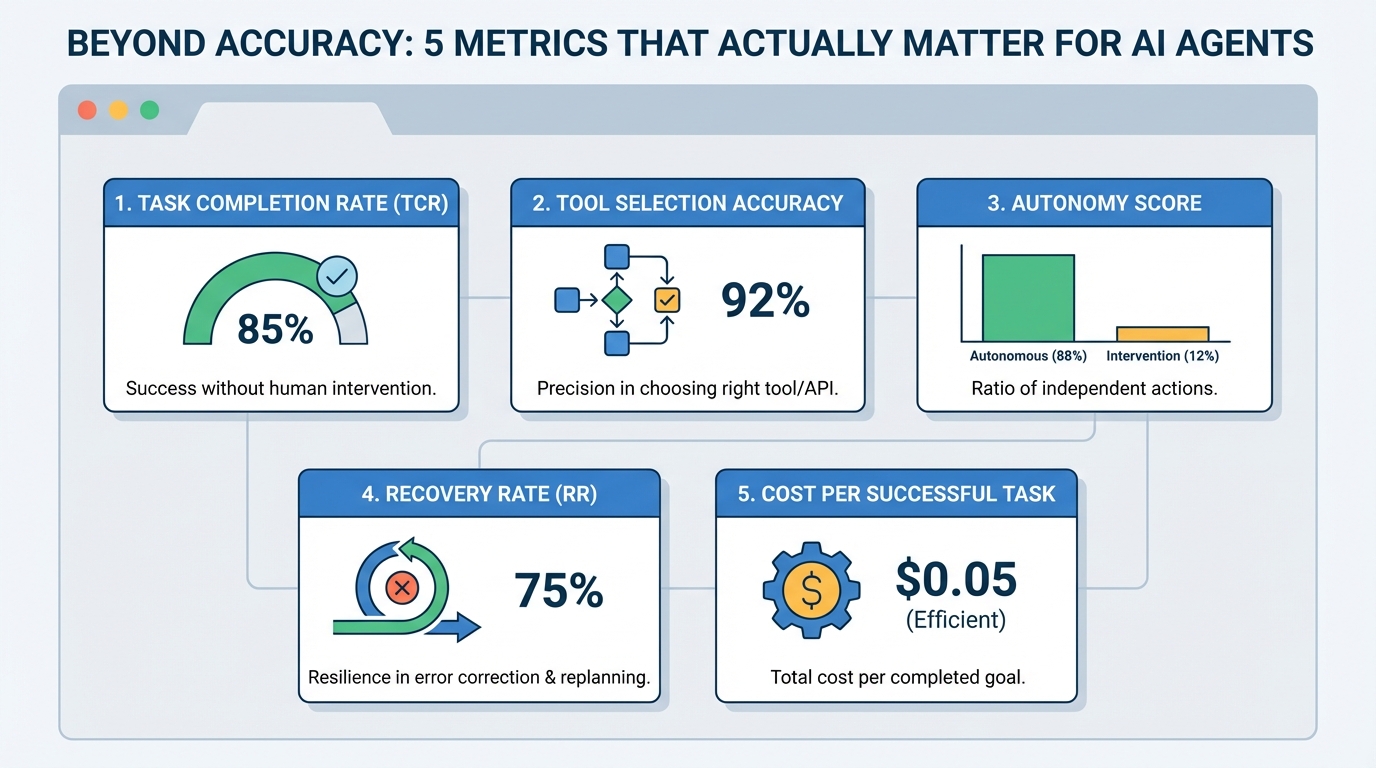
1. Task Completion Rate (TCR)
Also known as Success Rate, this metric measures the percentage of assigned tasks that are successfully carried out without the need for human supervision or intervention. Think of it as a measure of the agent’s ability to connect reasoning to a correct final outcome. For example, a customer support bot resolving a refund issue on its own could count toward this metric. Be warned: using this metric as a binary measure (success vs. failure) by itself can mask borderline cases or tasks that technically succeeded but took prohibitively long to complete.
Read more in this paper.
2. Tool Selection Accuracy
This measures how precisely the agent selects and executes the right function, external component, or API at a given step — in other words, how consistently it makes good selection-oriented decisions instead of acting randomly. Action selection becomes especially important in high-stakes domains like finance. To use this metric properly, you typically need a “ground truth” or “gold standard” path to compare against, which can be tricky to define in some contexts.
Read more in this overview.
3. Autonomy Score
Also referred to as the Human Intervention Rate, this is the ratio of actions taken autonomously by the agent to those that required some form of human intervention (clarification, correction, approvals, and so on). It is strongly related to the return on investment (ROI) of using AI agents. Bear in mind, though, that in critical domains like healthcare, low autonomy is not necessarily a bad thing. In fact, pushing autonomy too high can be a sign that safety guardrails are missing, so this metric must be interpreted in the context of the application.
Read more in this Anthropic research post.
4. Recovery Rate (RR)
How frequently does an agent identify an error and effectively replan to fix it? That is the core idea behind recovery rate: a metric for an agent’s resilience to unexpected outcomes, especially when it frequently interacts with tools and external systems outside its direct control. It requires careful interpretation, since a very high recovery rate can sometimes reveal underlying instability if the agent is correcting itself almost all the time.
Read more in this paper.
5. Cost per Successful Task
This metric is also described using names like token efficiency and cost-per-goal, but in essence, it measures the total computational or economic cost invested to complete one task successfully. This is an important metric to watch when planning to scale agent-based systems to handle higher volumes of tasks without cost surprises.
Read more in this guide.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.