![]()


Introduction: The Need for Efficient RL in LRMs
Reinforcement Learning RL is increasingly used to enhance LLMs, especially for reasoning tasks. These models, known as Large Reasoning Models (LRMs), generate intermediate “thinking” steps before providing final answers, thereby improving performance on complex problems such as math and coding. However, training LRMs with RL at scale is challenging due to the need for massive parallelization and efficient system design. Current systems often rely on synchronous batch processing, where generation must wait for the longest output in a batch to finish, leading to GPU underutilization. Even newer methods still face bottlenecks, as they use outdated rollouts but remain batch-based.
Background: Reinforcement Learning RL’s Impact on LLM Reasoning Abilities
Reinforcement Learning RL has become a widely used strategy to enhance the reasoning abilities of LLMs, particularly for tasks with clearly defined reward signals, such as math, coding, scientific reasoning, and tool use. These models typically improve by extending their chain-of-thought reasoning during training. Open-source efforts have shown that distilled, smaller models can also perform well on such tasks. Asynchronous RL methods, proven effective in gaming, have recently been explored for LLMs, but primarily in short-context or limited-overlap scenarios. Prior work has also investigated strategies, such as partial rollouts, to improve efficiency while maintaining training stability.
System Overview: Introducing AReaL
Researchers from IIIS, Tsinghua University, Ant Research, and HKUST introduce AReaL, a fully asynchronous reinforcement learning system designed to train large reasoning models more efficiently. Unlike traditional synchronous systems, AReaL separates the generation and training processes; rollout workers continuously produce outputs, while training workers update the model in parallel as new data arrives. This design enhances GPU usage and accelerates training. To handle data staleness, AReaL utilizes a tailored version of PPO and incorporates optimizations such as dynamic batching and parallel reward services. On math and code tasks, AReaL achieves up to 2.77× faster training while maintaining or improving final model performance.
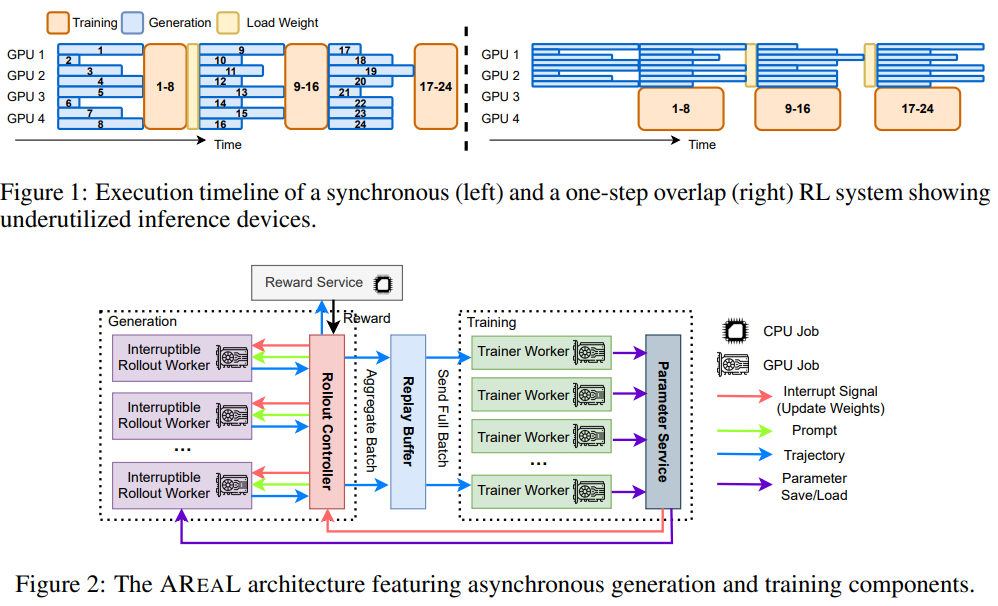
Technical Architecture: Key Components and Optimizations
AREAL is designed to decouple generation and training across separate GPU clusters, improving scalability, hardware efficiency, and flexibility for reinforcement learning with large models. The system includes four main components: rollout workers that support interruptible generation and model updates, a reward service that evaluates responses, trainer workers that perform PPO updates, and a controller that coordinates the data flow. To address challenges such as data staleness and inconsistent policy versions, AREAL employs staleness-aware training and a decoupled PPO objective. Additionally, system-level optimizations such as pipelined CPU-GPU operations, non-blocking asynchronous requests, and dynamic sequence packing enhance training speed and GPU efficiency.
Experimental Results: Scaling and Performance
AREAL was tested on math and coding tasks using distilled Qwen2 models of various sizes. It achieved 2–3 times faster training than prior methods, such as DeepScaleR and DeepCoder, while maintaining comparable accuracy. The system scales efficiently across GPUs and handles long context lengths (up to 32k tokens), outperforming synchronous methods’ key design features such as interruptible generation and dynamic microbatching, which boost training speed and hardware utilization. Algorithmically, AREAL’s decoupled PPO objective allows stable learning even with stale data, unlike standard PPO. Overall, AREAL balances speed and performance effectively, making it well-suited for large-scale RL training of language models.
Conclusion: Advancing Large-Scale RL for Language Models
In conclusion, AREAL is an asynchronous reinforcement learning system designed to enhance the efficiency of training LLMs, particularly for tasks such as coding and mathematical reasoning. Unlike traditional synchronous methods that wait for all outputs before updating, AREAL allows generation and training to run in parallel. This decoupling reduces GPU idle time and boosts throughput. To ensure learning remains stable, AREAL introduces staleness-aware strategies and a modified PPO algorithm that effectively handles older training data. Experiments show that it delivers up to 2.77 times faster training than synchronous systems, without sacrificing accuracy, marking a step forward in scaling up RL for large models.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
