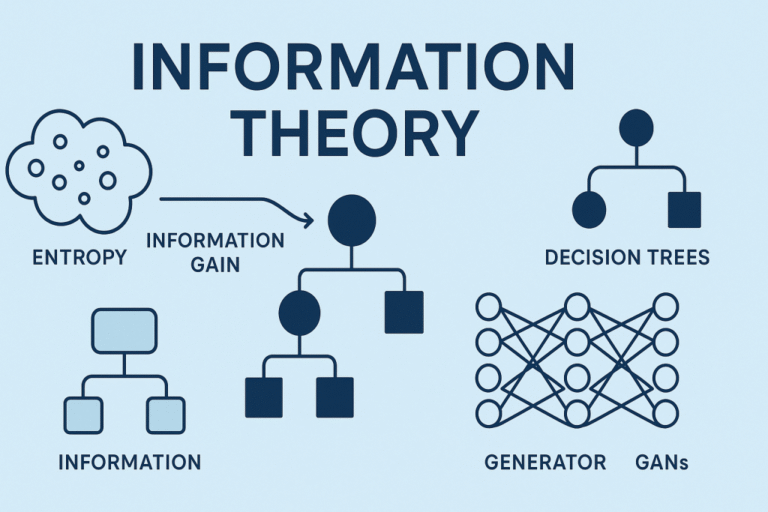
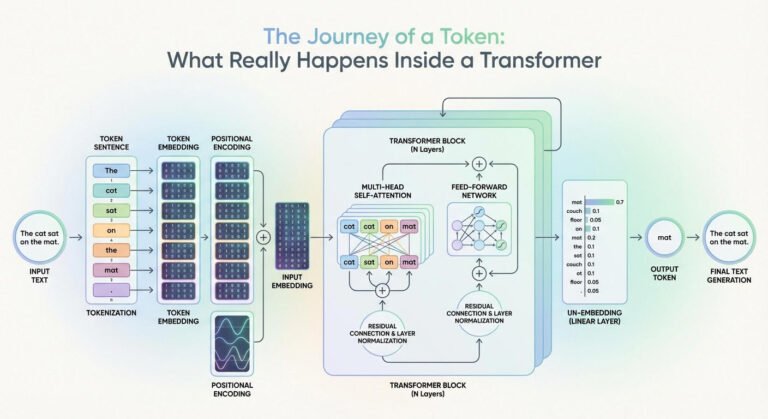
![]()


Google LiteRT NeuroPilot Stack Turns MediaTek Dimensity NPUs into First Class Targets for on Device LLMs
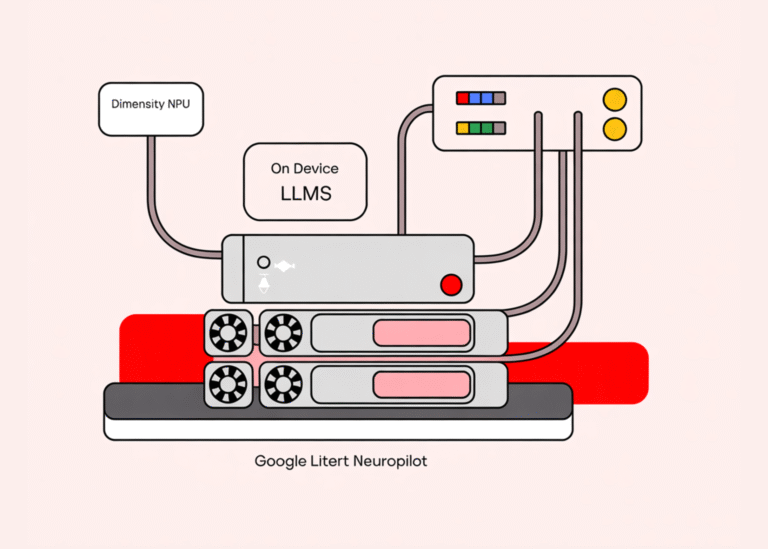
The new LiteRT NeuroPilot Accelerator from Google and MediaTek is a concrete step toward running real generative models on phones, laptops, and IoT hardware without shipping every request to a data center. It takes the existing LiteRT runtime and wires…