![]()


From ELIZA to Conversation Modeling: Evolution of Conversational AI Systems and Paradigms
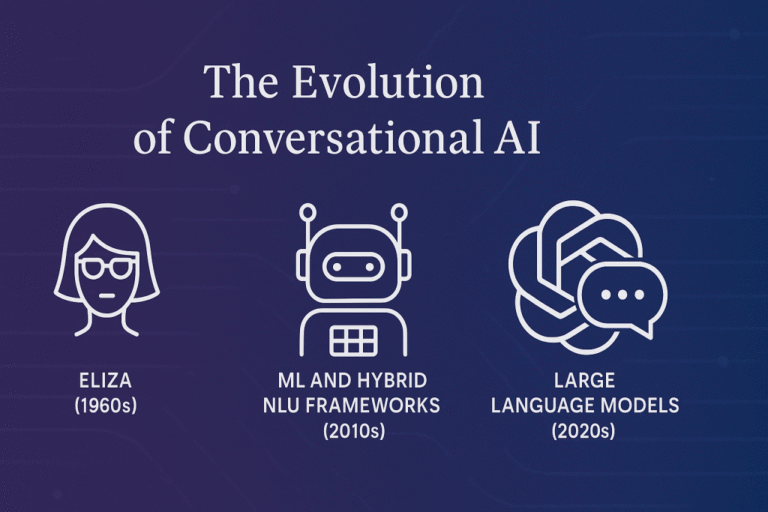
TL;DR: Conversational AI has transformed from ELIZA’s simple rule-based systems in the 1960s to today’s sophisticated platforms. The journey progressed through scripted bots in the 80s-90s, hybrid ML-rule frameworks like Rasa in the 2010s, and the revolutionary large language models…