![]()

NVIDIA AI Releases Describe Anything 3B: A Multimodal LLM for Fine-Grained Image and Video Captioning

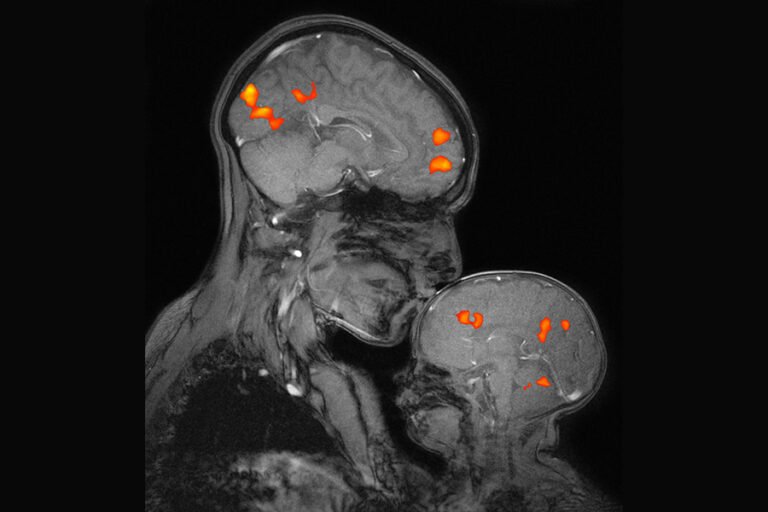
Challenges in Localized Captioning for Vision-Language Models Describing specific regions within images or videos remains a persistent challenge in vision-language modeling. While general-purpose vision-language models (VLMs) perform well at generating global captions, they often fall short in producing detailed, region-specific…