![]()

In this article, you will learn what small language models are, why they matter in 2026, and how to use them effectively in real production systems.
Topics we will cover include:
- What defines small language models and how they differ from large language models.
- The cost, latency, and privacy advantages driving SLM adoption.
- Practical use cases and a clear path to getting started.
Let’s get straight to it.
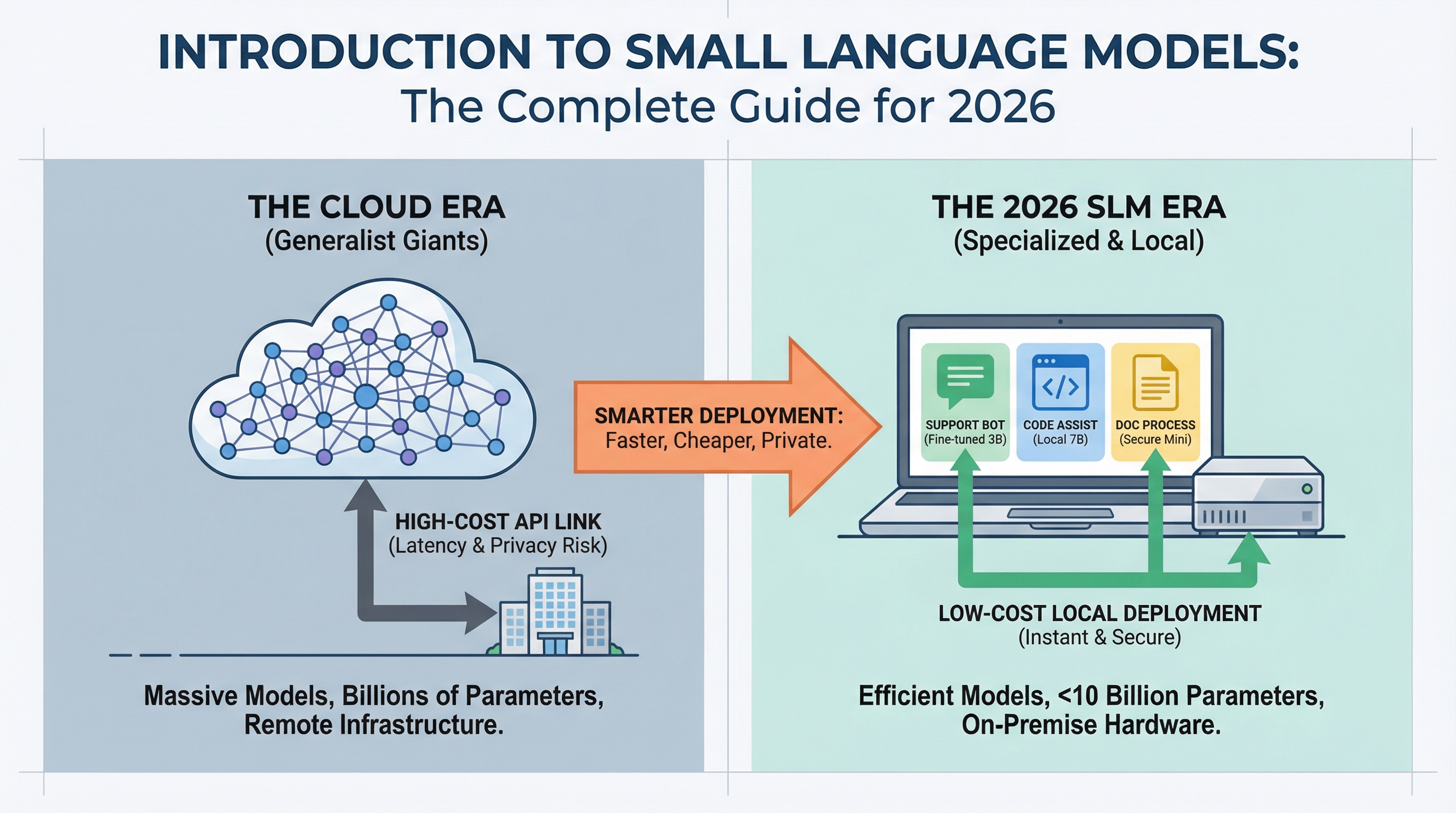
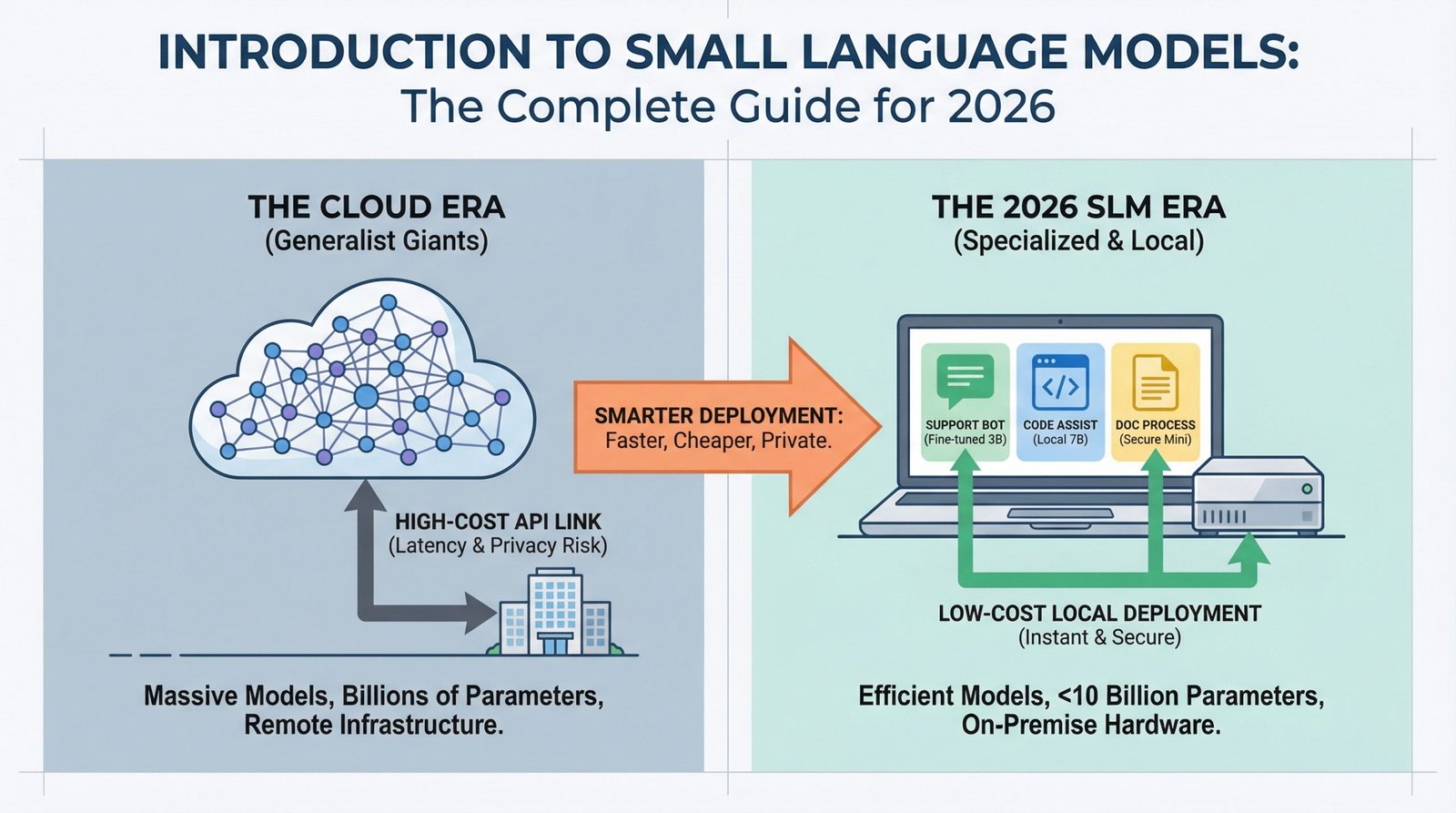
Introduction to Small Language Models: The Complete Guide for 2026
Image by Author
Introduction
AI deployment is changing. While headlines focus on ever-larger language models breaking new benchmarks, production teams are discovering that smaller models can handle most everyday tasks at a fraction of the cost.
If you’ve deployed a chatbot, built a code assistant, or automated document processing, you’ve probably paid for cloud API calls to models with hundreds of billions of parameters. But most practitioners working in 2026 are finding that for 80% of production use cases, a model you can run on a laptop works just as well and costs 95% less. If you want to jump straight into hands-on options, our guide to the Top 7 Small Language Models You Can Run on a Laptop covers the best models available today and how to get them running locally.
Small language models (SLMs) make this possible. This guide covers what they are, when to use them, and how they’re changing the economics of AI deployment.
What Are Small Language Models?
Small language models are language models with fewer than 10 billion parameters, usually ranging from 1 billion to 7 billion.
Parameters are the “knobs and dials” inside a neural network. Each parameter is a numerical value the model uses to transform input text into predictions about what comes next. When you see “GPT-4 has over 1 trillion parameters,” that means the model has 1 trillion of these adjustable values working together to understand and generate language. More parameters generally mean more capacity to learn patterns, but they also mean more computational power, memory, and cost to run.
The scale difference is significant. GPT-4 has over 1 trillion parameters, Claude Opus has hundreds of billions, and even Llama 3.1 70B is considered “large.” SLMs operate at a completely different scale.
But “small” doesn’t mean “simple.” Modern SLMs like Phi-3 Mini (3.8B parameters), Llama 3.2 3B, and Mistral 7B deliver performance that rivals models 10× their size on many tasks. The real difference is specialization.
Where large language models are trained to be generalists with broad knowledge spanning every topic imaginable, SLMs excel when fine-tuned for specific domains. A 3B model trained on customer support conversations will outperform GPT-4 on your specific support queries while running on hardware you already own.
You Don’t Build Them From Scratch
Adopting an SLM doesn’t mean building one from the ground up. Even “small” models are far too complex for individuals or small teams to train from scratch. Instead, you download a pre-trained model that already understands language, then teach it your specific domain through fine-tuning.
It’s like hiring an employee who already speaks English and training them on your company’s procedures, rather than teaching a baby to speak from birth. The model arrives with general language understanding built in. You’re just adding specialized knowledge.
You don’t need a team of PhD researchers or massive computing clusters. You need a developer with Python skills, some example data from your domain, and a few hours of GPU time. The barrier to entry is much lower than most people assume.
Why SLMs Matter in 2026
Three forces are driving SLM adoption: cost, latency, and privacy.
Cost: Cloud API pricing for large models runs \$0.01 to \$0.10 per 1,000 tokens. At scale, this adds up fast. A customer support system handling 100,000 queries per day can rack up $30,000+ monthly in API costs. An SLM running on a single GPU server costs the same hardware whether it processes 10,000 or 10 million queries. The economics flip entirely.
Latency: When you call a cloud API, you’re waiting for network round-trips plus inference time. SLMs running locally respond in 50 to 200 milliseconds. For applications like coding assistants or interactive chatbots, users feel this difference immediately.
Privacy: Regulated industries (healthcare, finance, legal) can’t send sensitive data to external APIs. SLMs let these organizations deploy AI while keeping data on-premise. No external API calls means no data leaves your infrastructure.
LLMs vs SLMs: Understanding the Trade-offs
The decision between an LLM and an SLM depends on matching capability to requirements. The differences come down to scale, deployment model, and the nature of the task.
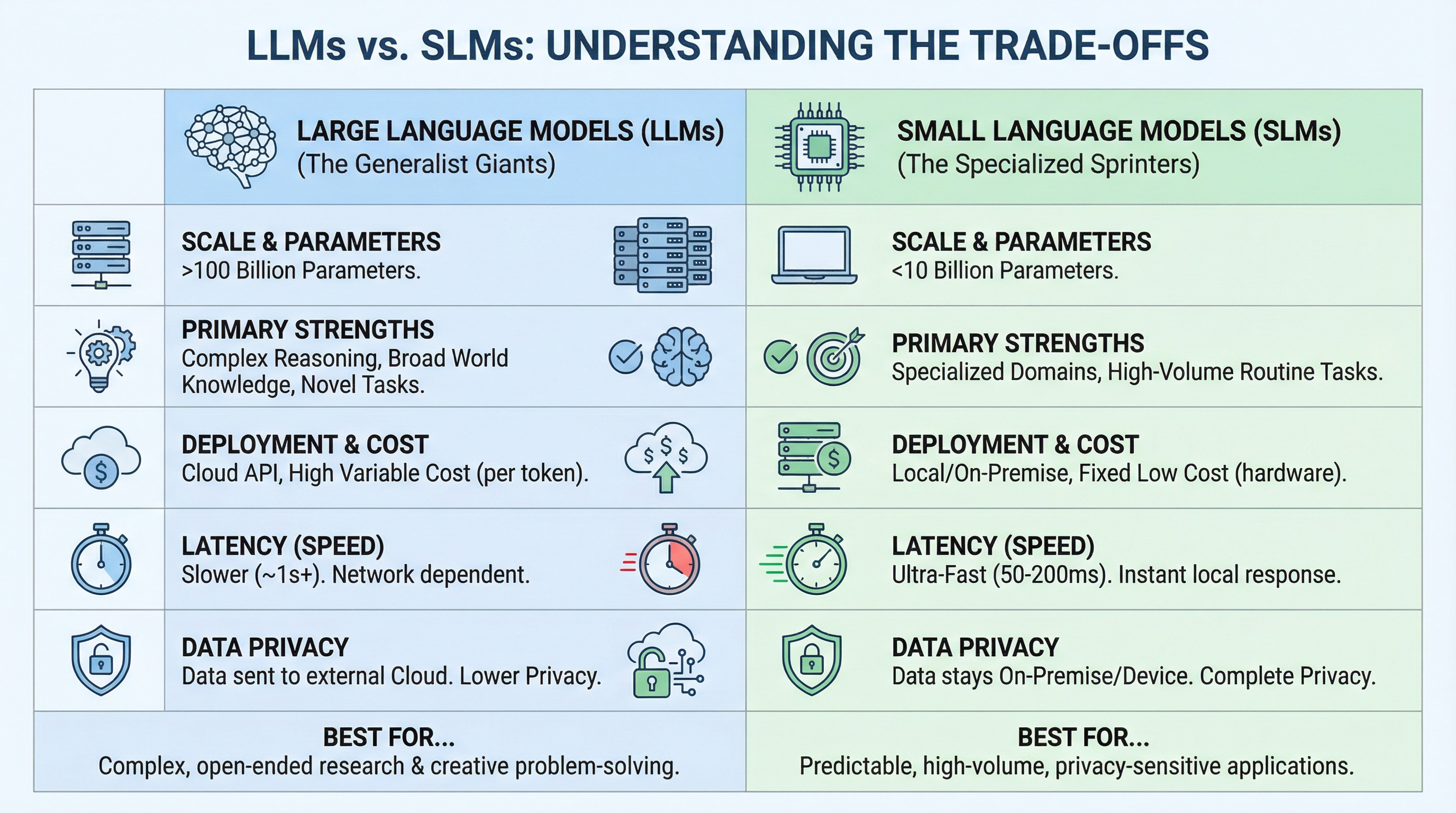
The comparison reveals a pattern: LLMs are designed for breadth and unpredictability, while SLMs are built for depth and repetition. If your task requires handling any question about any topic, you need an LLM’s broad knowledge. But if you’re solving the same type of problem thousands of times, an SLM fine-tuned for that specific domain will be faster, cheaper, and often more accurate.
Here’s a concrete example. If you’re building a legal document analyzer, an LLM can handle any legal question from corporate law to international treaties. But if you’re only processing employment contracts, a fine-tuned 7B model will be faster, cheaper, and more accurate on that specific task.
Most teams are landing on a hybrid approach: use SLMs for 80% of queries (the predictable ones), escalate to LLMs for the complex 20%. This “router” pattern combines the best of both worlds.
How SLMs Achieve Their Edge
SLMs aren’t just “small LLMs.” They use specific techniques to deliver high performance at low parameter counts.
Knowledge Distillation trains smaller “student” models to mimic larger “teacher” models. The student learns to replicate the teacher’s outputs without needing the same massive architecture. Microsoft’s Phi-3 series was distilled from much larger models, retaining 90%+ of the capability at 5% of the size.
High-Quality Training Data matters more for SLMs than sheer data quantity. While LLMs are trained on trillions of tokens from the entire internet, SLMs benefit from curated, high-quality datasets. Phi-3 was trained on “textbook-quality” synthetic data, carefully filtered to remove noise and redundancy.
Quantization compresses model weights from 16-bit or 32-bit floating point to 4-bit or 8-bit integers. A 7B parameter model in 16-bit precision requires 14GB of memory. Quantized to 4-bit, it fits in 3.5GB (small enough to run on a laptop). Modern quantization techniques like GGUF maintain 95%+ of model quality while achieving 75% size reduction.
Architectural Optimizations like sparse attention reduce computational overhead. Instead of every token attending to every other token, models use techniques like sliding-window attention or grouped-query attention to focus computation where it matters most.
Production Use Cases
SLMs are already running production systems across industries.
Customer Support: A major e-commerce platform replaced GPT-3.5 API calls with a fine-tuned Mistral 7B for tier-1 support queries. They saw a 90% cost reduction, 3× faster response times, and equal or better accuracy on common questions. Complex queries still escalate to GPT-4, but 75% of tickets are handled by the SLM.
Code Assistance: Development teams run Llama 3.2 3B locally for code completion and simple refactoring. Developers get instant suggestions without sending proprietary code to external APIs. The model was fine-tuned on the company’s codebase, so it understands internal patterns and libraries.
Document Processing: A healthcare provider uses Phi-3 Mini to extract structured data from medical records. The model runs on-premise, HIPAA-compliant, processing thousands of documents per hour on standard server hardware. Previously, they avoided AI entirely due to privacy constraints.
Mobile Applications: Translation apps now embed 1B parameter models directly in the app. Users get instant translations without internet connectivity. Battery life is better than cloud API calls, and translations work on flights or in remote areas.
When not to use SLMs: Open-ended research questions, creative writing requiring novelty, tasks needing broad knowledge, or complex multi-step reasoning. An SLM won’t write a novel screenplay or solve novel physics problems. But for well-defined, repeated tasks, they’re ideal.
Getting Started with SLMs
If you’re new to SLMs, start here.
Run a quick test. Install Ollama and run Llama 3.2 3B or Phi-3 Mini on your laptop. Spend an afternoon testing it on your actual use cases. You’ll immediately understand the speed difference and capability boundaries.
Identify your use case. Look at your AI workloads. What percentage are predictable, repeated tasks versus novel queries? If more than 50% are predictable, you have a strong SLM candidate.
Fine-tune if needed. Collect 500 to 1,000 examples of your specific task. Fine-tuning takes hours, not days, and the performance improvement can be significant. Tools like Hugging Face’s Transformers library and platforms like Google Colab make this accessible to developers with basic Python skills.
Deploy locally or on-premise. Start with a single GPU server or even a beefy laptop. Monitor cost, latency, and quality. Compare against your current cloud API spend. Most teams find ROI within the first month.
Scale with a hybrid approach. Once you’ve proven the concept, add a router that sends simple queries to your SLM and complex ones to a cloud LLM. This works well for both cost and capability.
Key Takeaways
The trend in AI isn’t just “bigger models.” It’s smarter deployment. As SLM architectures improve and quantization techniques advance, the gap between small and large models narrows for specialized tasks.
In 2026, successful AI deployments aren’t measured by which model you use. They’re measured by how well you match models to tasks. SLMs give you that flexibility: the ability to deploy capable AI where you need it, on hardware you control, at costs that scale with your business.
For most production workloads, the question isn’t whether to use SLMs. It’s which tasks to start with first.