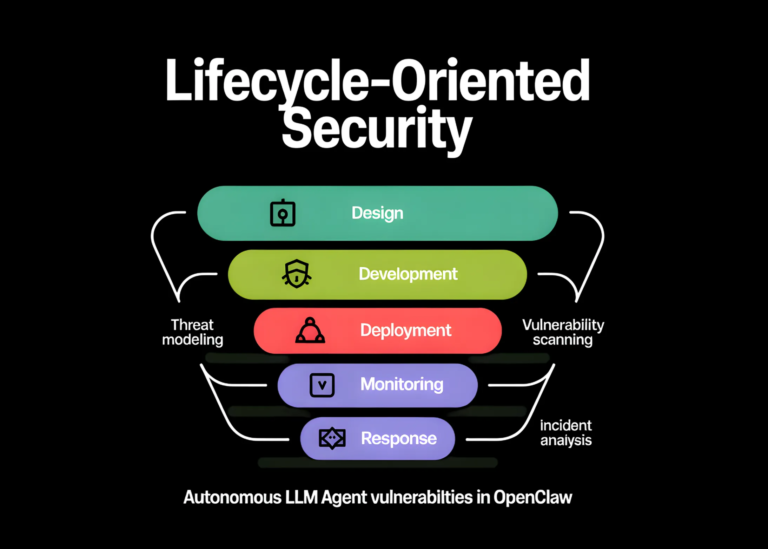
![]()


A better method for identifying overconfident large language models | MIT News

Large language models (LLMs) can generate credible but inaccurate responses, so researchers have developed uncertainty quantification methods to check the reliability of predictions. One popular method involves submitting the same prompt multiple times to see if the model generates the…