![]()


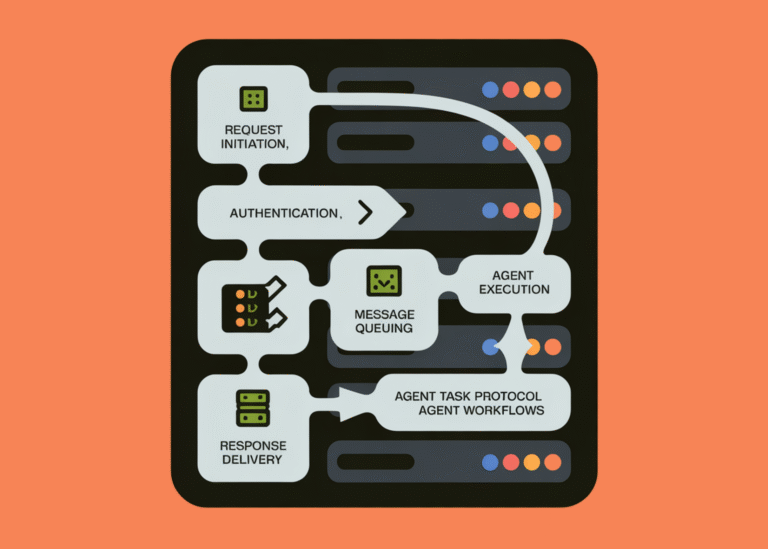
NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x Compression
As context lengths move into tens and hundreds of thousands of tokens, the key value cache in transformer decoders becomes a primary deployment bottleneck. The cache stores keys and values for every layer and head with shape (2, L, H,…