![]()


Google AI Releases Gemini CLI: An Open-Source AI Agent for Your Terminal
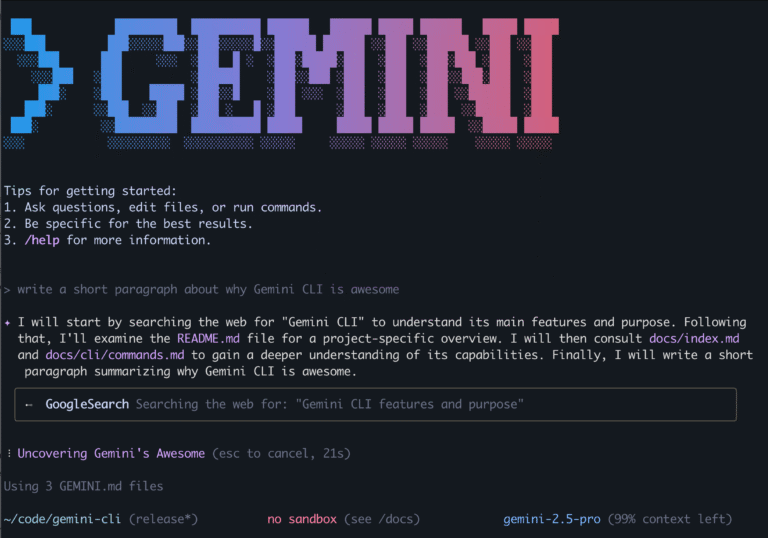
Google has unveiled Gemini CLI, an open-source command-line AI agent that integrates the Gemini 2.5 Pro model directly into the terminal. Designed for developers and technical power users, Gemini CLI allows users to interact with Gemini using natural language directly…








