![]()


LightOn AI Released GTE-ModernColBERT-v1: A Scalable Token-Level Semantic Search Model for Long-Document Retrieval and Benchmark-Leading Performance
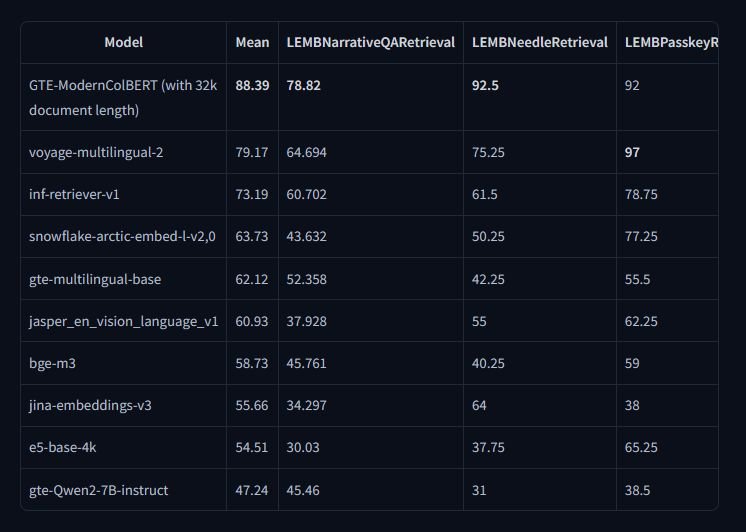
Semantic retrieval focuses on understanding the meaning behind text rather than matching keywords, allowing systems to provide results that align with user intent. This ability is essential across domains that depend on large-scale information retrieval, such as scientific research, legal…