![]()

Sports
Safely Deploying ML Models to Production: Four Controlled Strategies (A/B, Canary, Interleaved, Shadow Testing)
Deploying a new machine learning model to production is one of the most critical stages of the ML lifecycle. Even if a model performs well on validation and test datasets, directly replacing the existing production model can be risky. Offline evaluation rarely captures the full complexity of real-world environments—data distributions may shift, user behavior…
A Coding Implementation to Build an Uncertainty-Aware LLM System with Confidence Estimation, Self-Evaluation, and Automatic Web Research
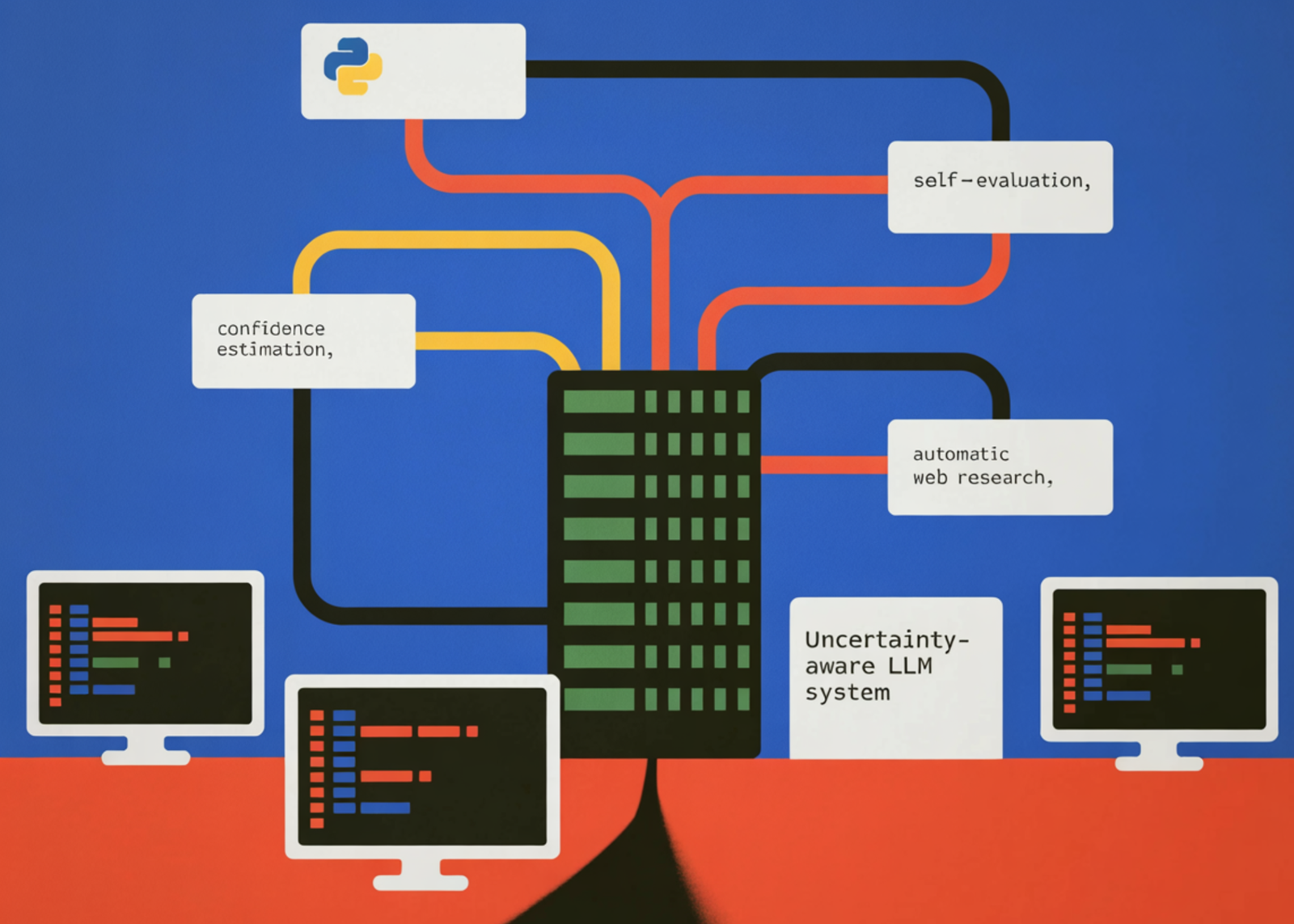
In this tutorial, we build an uncertainty-aware large language model system that not only generates answers but also estimates the confidence in those answers. We implement a three-stage reasoning pipeline in which the model first produces an answer along with a self-reported confidence score and a justification. We then introduce a self-evaluation step that…
NVIDIA Releases Nemotron-Cascade 2: An Open 30B MoE with 3B Active Parameters, Delivering Better Reasoning and Strong Agentic Capabilities

NVIDIA has announced the release of Nemotron-Cascade 2, an open-weight 30B Mixture-of-Experts (MoE) model with 3B activated parameters. The model focuses on maximizing ‘intelligence density,’ delivering advanced reasoning capabilities at a fraction of the parameter scale used by frontier models. Nemotron-Cascade 2 is the second open-weight LLM to achieve Gold Medal-level performance in the…
A Coding Implementation Showcasing ClawTeam’s Multi-Agent Swarm Orchestration with OpenAI Function Calling

SWARM_TOOLS = [ { “type”: “function”, “function”: { “name”: “task_update”, “description”: “Update the status of a task. Use ‘in_progress’ when starting, ‘completed’ when done.”, “parameters”: { “type”: “object”, “properties”: { “task_id”: {“type”: “string”, “description”: “The task ID”}, “status”: {“type”: “string”, “enum”: [“in_progress”, “completed”, “failed”]}, “result”: {“type”: “string”, “description”: “Result or output of the task”},…
What’s the right path for AI? | MIT News

Who benefits from artificial intelligence? This basic question, which has been especially salient during the AI surge of the last few years, was front and center at a conference at MIT on Wednesday, as speakers and audience members grappled with the many dimensions of AI’s impact.In one of the conferences’s keynote talks, journalist Karen…
MIT and Hasso Plattner Institute establish collaborative hub for AI and creativity | MIT News

The following is a joint announcement from the MIT School of Architecture and Planning, MIT Schwarzman College of Computing, Hasso Plattner Institute, and Hasso Plattner Foundation.The MIT Morningside Academy for Design (MAD), MIT Schwarzman College of Computing, Hasso Plattner Institute (HPI), and Hasso Plattner Foundation celebrated the launch of the MIT and HPI AI…